




In this post, we’ll take a look at how to query BigQuery data in batches using Python and the bigquery client package. BigQuery is a fully managed data warehouse for analytics on the Google Cloud Platform.
Motivation
A number of teams at SeekandHit often work with BigQuery. It is basically the go to table for ingesting data that is used by different analytics teams, regardless of whether the data is generated by our systems, or collected from third-party APIs. The team that I am part of uses BigQuery for storing data related to marketing campaigns, SEO, and mobile app statistics. We also use it to store some data that is generated by other teams.
We can categorize our own usage of BigQuery into the following categories:
Ingesting data collected from APIs
Storing file contents to tables
Querying and using data from other teams
Writing and manually running SQL queries to see if everything is working correctly.
This data is later used for a wide range of applications – from generating reports, building models, determining what to market, and driving other services. In this post we’ll take a look at how to query the data from BigQuery.
Querying data
Some of our projects use data ingested by other teams or ourselves. Multiple services that we have use BigQuery data to generate various types of files. However, the problem is that our services usually have multiple data pipelines running concurrently. And, of course, we have a limited amount of RAM. Since we don’t know how many rows the source table will contain at every given moment, sometimes memory spikes occur. E.g.

The image above shows a memory spike that occurred in one of our services on April 16th between 2:00 AM and 2:26 AM.
This particular service runs some 30+ queries daily, each in an instance of a data pipeline. Since the service runs these pipelines daily, the first thing we did was to make sure that the pipelines are scheduled in a way that their runs don’t overlap. Meaning that we scheduled each pipeline to start at a time we are fairly certain other pipelines are not running.
Of course, this doesn’t eliminate the problem of loading large amounts of data into a single pipeline run. Therefore, we need to look at how to load data from BigQuery in batches (or pages in BigQuery terminology).
So, let’s take a look at how we can paginate through the data.
The example in the docs
I would like to touch on the example provided in the docs on this page [1].

The “problem” with this example is that you need to take care to remember the next page token. The page token tells the service where you left off and from which page you want to continue. This is good if you want to skip some pages or simply have more control. However, in our use case, we want to load all of the data.
Let’s take a look at how we do it and what happens under the hood.
The table that we will use
Google offers a number of datasets that are available to the general public. One of these is the google_trends dataset that I chose for this example. A dataset is a collection of tables. We’ll use the international_top_rising_terms table for this example. I chose it because it:
Has a large number of rows,
The table is partitioned – meaning we can query the data for a single day without scanning the entire table.
The example
For this example, I’m gonna use Python 3.11.3 along with the google-cloud-bigquery package version 3.11.0. The example assumes that you have an environment variable GOOGLE_BIGQUERY_CREDENTIALS that contains the credentials encoded as a base64 string.
Let’s start by defining a function for creating our credentials.

I’ve placed this function into the auth.py module.
Let’s go through the steps of the example, the full code is available at the end of the post.
First, we import the required packages, including the function we previously defined:

Nothing special going on here. We start by implementing a function that will run the query:

The function above accepts the query we want to execute as a string. It then declares a variable for our result.
In the next step we create a BigQuery client using the function we previously wrote (get_bq_client). Using the bigquery.Client instance, we can call the query method and pass the query argument to it. This method returns a QueryJob instance.
Calling the result method on the job instance starts the job and waits for the result. The query job result will be an iterator instance. We print out the total number of rows that the table has.
If any exceptions occur, we print out a message. Finally, we return the query job result.
I also decided to wrap this function into a get_data function that will return a generator. Each element returned by the generator will be a page (or batch). Here is the implementation:

The function first calls the previous function and checks whether the result is None. If it’s None, just return an empty list. Otherwise, we iterate through the pages (batches) and return them one by one.
Now, we only need to write our BigQuery SQL query, call the get_data function and iterate over the generator of pages (batches).

We’re querying the data from the public dataset’s table for June 7th. If we run the script now, we’ll get the following output (assuming everything goes well):

Now… it would have taken some 178 iterations to get all of the pages, given the current page size, but you get the idea 😀.
The page size (in this case) is a “sensible value set by the API”. When working on one of our production tables, we got back 175 000 rows per page. However, there is a maximum size that the response object can have (see [1]). Despite trying, I wasn’t able to get a response larger than 35 000 rows in this example.
Ok, so, that was our basic example, but what happens under the hood? Are we sure that the data is loaded from BigQuery in batches? Let’s take a look…
If you’re not interested in what happens under the hood… feel free to skip to the conclusion.
What happens under the hood?
If you take a look at the link provided under [1], you’ll notice this:
“Each query writes to a destination table. If no destination table is provided, the BigQuery API automatically populates the destination table property with a reference to a temporary anonymous table.”
That means that each query that we run through the BigQuery client will create a temporary table for us. The reference to the destination table will be available in the destination property of the QueryJob instance. We get the job instance from calling the bigquery.Client.query method.
Ok, so, when we page through the results, the data is read from this table. I already mentioned that calling the method result on the bigquery.job.QueryJob instance returns an iterator. This iterator is actually an instance of bigquery.table.RowIterator.
The bigquery.table.RowIterator class inherits the page_iterator.HttpIterator class defined in the google.api_core package. Here is the inheritance diagram for these classes (only the fields and methods relevant to the discussion are included):
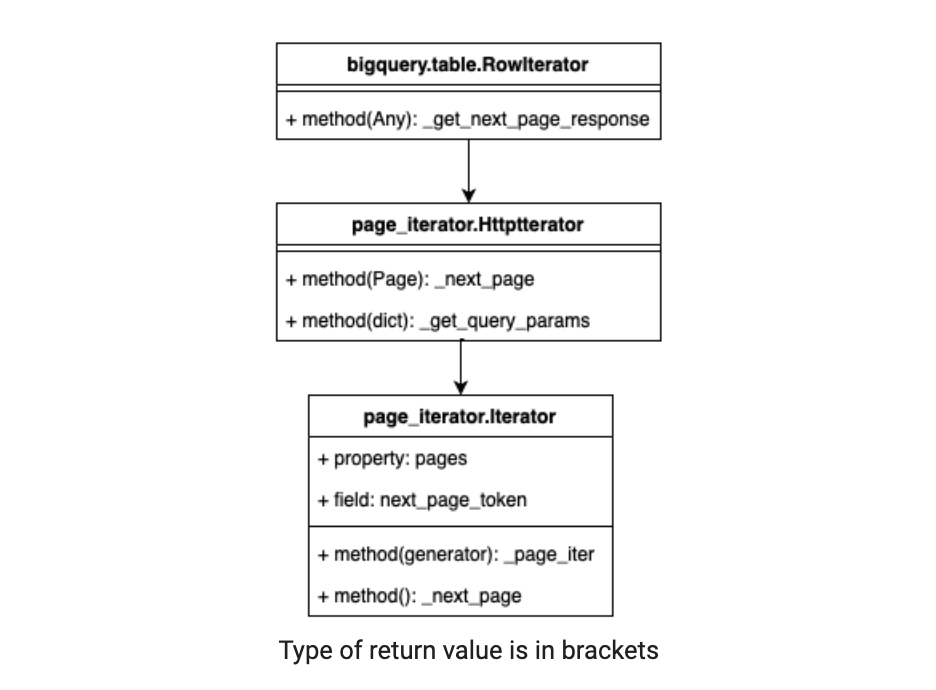
When we call the pages property, it is defined in the page_iterator.Iterator class. Meaning that this property is inherited. Calling the property will raise an exception if an iteration has already started. Otherwise, it will return the result of calling the _page_iter method. Notice that this is a private method.
In turn, the _page_iter method will yield a page returned by calling the _next_page method (this means it returns a generator). Let’s take a look:
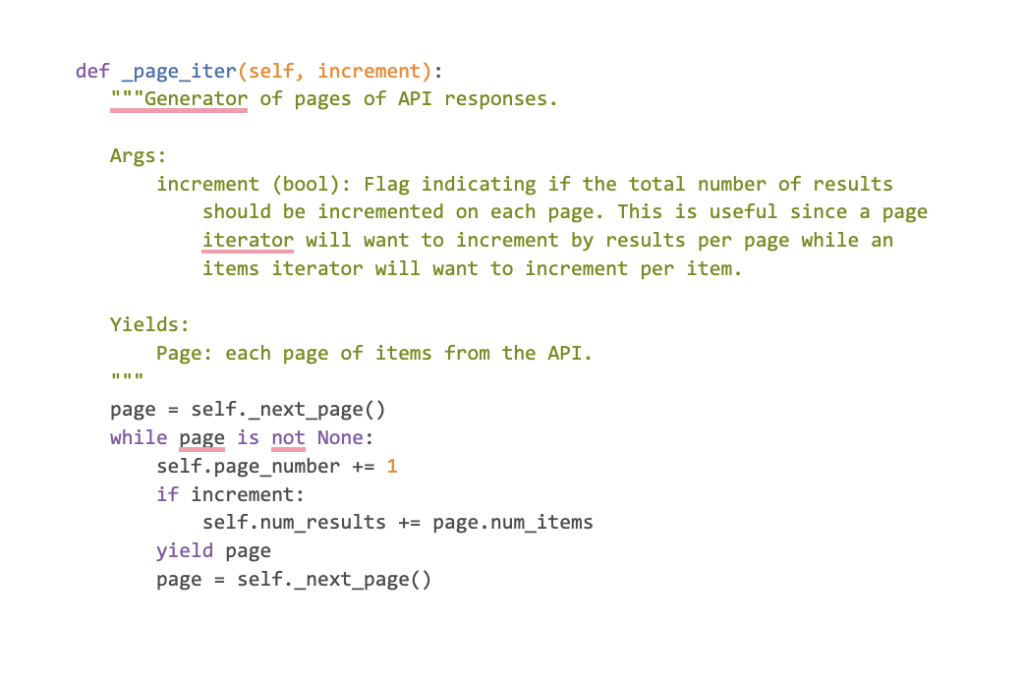
The _next_page method is abstract. Therefore the classes that inherits the page_iterator.Iterator class must implement it.
The page_iterator.HttpIterator class implements this method. Here is it’s implementation:
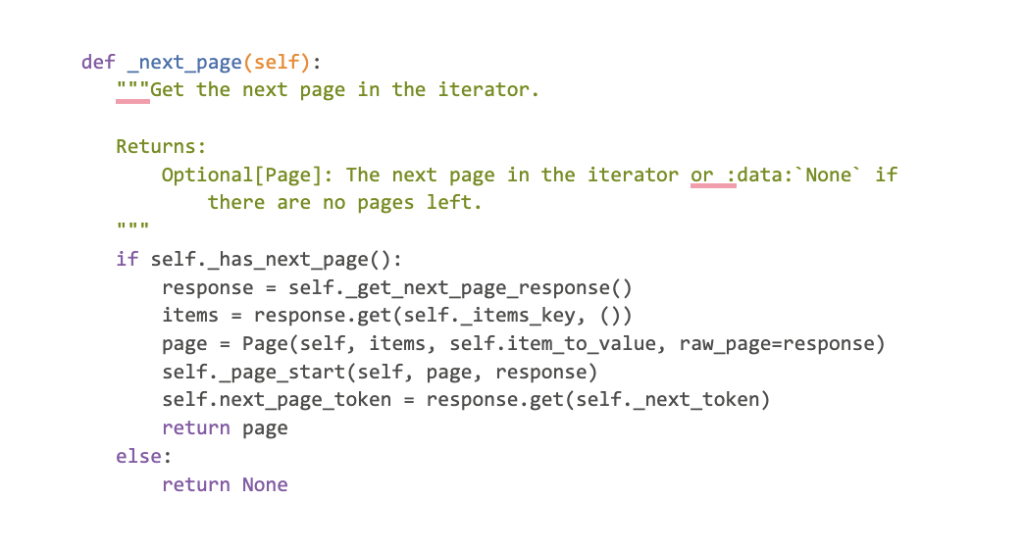
As you can see, the method internally calls the _get_next_page_response method, extracts the obtained items (rows) and wraps them inside the Page class. It also gets the next page token from the response. The Page class represents a single page of results in an iterator. You can actually get the reference to the actual response from the page instance using page.raw_page.
The self._page_start is assigned to a function provided as a constructor argument. This function is used to do something after a new Page instance is created. I won’t go into much details about it, but the RowIterator provides a function called _rows_page_start which gets the total number of rows from the response and the columns schema from the rows that are returned as part of the response.
The RowIterator actually overrides the _get_next_page_response method defined in the HTTPIterator. Let’s look at the override implementation:

The most important point here is that the method makes API requests to Google. The query parameters that it constructs contain the next page token obtained from the previous response. Here is the relevant part of the method (defined in HTTPIterator):

So, in essence, the pages property returns a generator. When we loop through the generator, the HTTPIterator makes an API request for each new page that needs to be generated. The RowIterator provides the function that obtains the total number of rows from the response and table schema.
Conclusion
In this post, we took a look at how to query a BigQuery table from Python using the client library google-cloud-bigquery.
We also took a look under the hood of how this happens. For each query we execute, BigQuery creates a table. When paging through the result, the next page token is used to determine the next page for iteration and an API request is sent to fetch the page. We can use the RowIterator, in which case this is done for us, or we can do it manually.
If you want to have full control over paging through the results of a query, then the example provided in [1] is a good starting point. You can also take a look at the _next_page, _get_next_page_response, and _get_query_params methods implementations.


