




This blog is the second part of the Valid Tracking Data? Yes, Please blog about the implementation of QA techniques into marketing campaigns.
While the first part of the blog covers the reasons for such implementation and a basic overview on how to implement them, this second part covers the steps to implement QA into tracking workflows.
Implementing QA into tracking
In the latter blog we agreed what we need to test, and now it remains to decide on how to test.
Before we get into the nitty gritty details on how to implement the actual testing of your tracking configuration we need to explain how Quality Assurance (QA), i.e. testing, fits into the workflow of your tracking teams.
Let’s say the following is a typical example of a tracking team workflow:
1. Product Backlog Refinement: Involves defining and prioritizing tracking requirements in collaboration with stakeholders.
2. Sprint Planning: Selecting user stories, estimate effort, and commit to a sprint goal, addressing technical considerations and dependencies.
3. Daily Standup Meetings: Share project progress, discuss challenges, and plan daily work, highlighting and resolving impediments.
4. Implementation: Develop and implement tracking codes using Google Tag Manager, ensuring alignment with analytics requirements.
5. Testing
6. Sprint Review: Showcase completed tracking implementations, gather stakeholder feedback, and make necessary adjustments.
7. Sprint Retrospective: Reflect on the sprint, identify areas for improvement, and commit to action items for process enhancement.
8. Backlog Grooming and Planning for Next Sprint: Refine and reprioritize tracking requirements, plan the next sprint, and incorporate lessons learned.
The question, though, is where QA fits into this. The obvious answer is the 5th step – testing; however, this is only partially correct. Truth to be told is you should involve QA as early as possible in the process (meaning Backlog refinement) and keep it there with its big nose poking around for potential issues.
However, for the moment this falls a bit outside the scope of this article so we’ll say that QA comes in at step 5: Testing.
You might have noticed I didn’t include a definition for Testing, and there’s the reason for that. Primarily, it encompasses a wide range of activities, making it difficult to define in simple terms. Moreover, it overlaps with most of the other steps in the workflow. Lastly, because I’ll define it in broad strokes below.
At the moment, we’ve reached the stage where we (partially) understand where QA fits in. Now, the tracking team needs to integrate their expertise into the team’s workflow. Since a big chunk of this process falls outside the scope of this article let’s just say that the QA and Tracking teams are already perfectly integrated and all that’s left is the actual testing part.
So, how do we approach this? Manual testing is an option to ensure the implementation goes as expected, but it’s time-consuming, error-prone, and tedious—especially when the person could be focusing on far more valuable tasks. This is particularly true if the tester is a tracking specialist who should be dedicating their time to the finer details of the tracking implementation.
If manual testing then isn’t the answer, what’s left? Well, of course, automated validation! And that’s what we did for our tracking team.
Automated validation
There are so many different choices for use when it comes to automation testing that are easy to get bogged down. We needed a solution fast to implement, easy to set up and that is reliable, fast, and efficient in its execution.
Playwright emerged as a preferred choice due to its user-friendly nature, rapid execution speed, streamlined implementation process, robust community support, and extensive, and well-maintained documentation, bolstered by Microsoft’s continuous commitment to its development and enhancement.
Our prior experience with Playwright, particularly in a project involving the migration of an entire framework from Selenium/Python to Playwright/Python (shoutout to our colleague Anđela who made this happen), reinforced its credibility and efficiency. Such a successful transition showcased not only Playwright’s adaptability but also underscored its superiority in terms of performance and maintenance compared to other testing frameworks.
Pairing Playwright with TypeScript was a strategic move aligned with our pursuit of stronger type safety and enhanced code reliability. While acknowledging the occasional challenges inherent in a strongly typed language (it can get tedious at times), it benefits in minimizing errors and enhancing code maintainability were evident. The robust support and comprehensive documentation provided by Microsoft further solidified our choice of TypeScript, augmenting our confidence in creating a more resilient and efficient tracking validation framework.
So we chose the technology, but what to do with it? In Essentially, we wanted to buidl our framework on Playwright and TypeScript to mirror real-world user interactions on websites, specifically targeting Google Tag Manager (GTM) events.
Since that was a large chunk of text here’s a nice flowchart explaining how the whole process is streamlined.

So how does this all actually look like? Here’s a sneak peek.
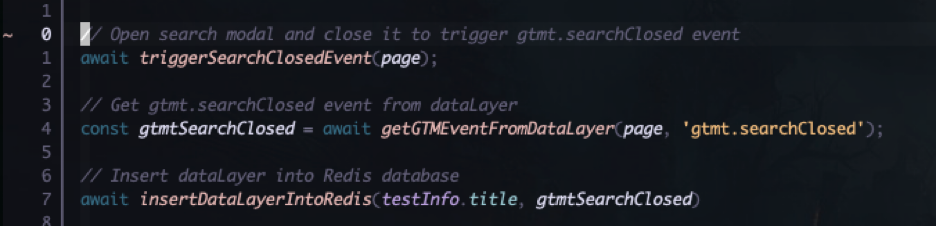
I think it’s pretty self explanatory but in essence the first line triggers a GTM event by opening a search bar and simply closing it straight after. The second function call retrieves the entire dataLayer object and then filters only the gtmt.searchClosed event and stores it in a variable. Lastly we insert that dataLayer object into the database as a key value pair. The key being the test title and the value being the dataLayer object associated with it.
So now we have triggered the GTM event and have stored the dataLayer object associated with it.
Beyond merely triggering these events, our framework delves deeper by retrieving event data from the page’s dataLayer object and validating it. This validation process occurs immediately after an event triggers, ensuring the occurrence of the intended event and verifying the presence of all required GTM variables (in programming terms these would be the dataLayer object properties).
Another sneak peek (if I continue doing this I might as well grant you access to the entire codebase).
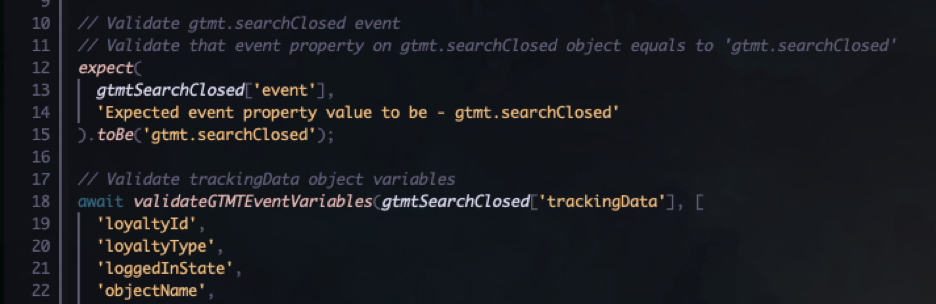
First part uses Playwrights’ built in expect function to assert that the event name we triggered and saved to a variable is what we expect it to be, in this case gtmt.searchClosed.
Second part is a function that checks all of the fields in the trackingData property of the dataLayer object. It validates that all of the expected properties (in Tracking terms we would call them variables) are present and also that no additional properties are there.
If you’re familiar at all with how a dataLayer object looks (or any old javascript object for that matter) you will know that other than the structure and the properties you can and should also validate the values of these properties. Below you will find an example of a dataLayer object.
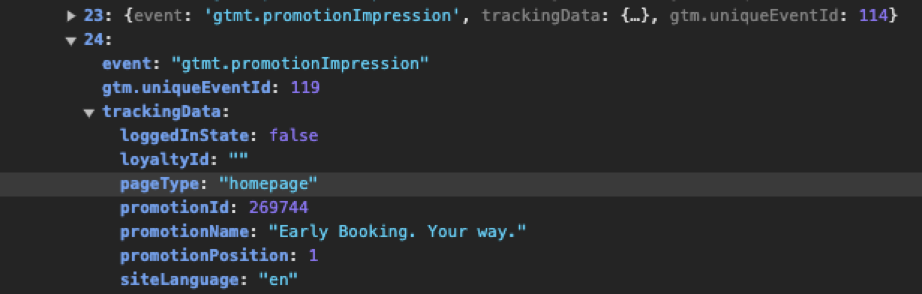
As you can see some of these properties have empty values and some do not, but both need to be validated. But how to do this?
We just hard coded some static values, however, a lot of them weren’t static but dependent on what and where the event was triggered. Originally we thought about scraping the values from the website but soon found out that this would be too time consuming and would require regular updates to the code from our end. In short we didn’t want to waste time on minor implementation details. The idea was once you build it, it works with little to no maintenance from the developers perspective.
How to do it?
As almost always, the solution was quite simple once we found it. The thing is that we (or rather the tracking team) already stores these values (which unfortunately we didn’t take into account at the beginning) 🤦🏻♂️.
They’re kept in Google’s Big Query so all we need to do is compare the dataLayer we have in our test, or rather the variable values we have to what’s stored on Big Query.
The first step, thus, was to save the dataLayer objects we triggered in our tests somewhere so we could access them later on. After some investigation we came to the conclusion that within each test, after the dataLayer object is available we should just store it in some database for later use. Redis rose up as the best option here as its simplicity and performance (not to mention the free tier which is all we needed basically) won us over. One function definition later and some function calls (in which we stored the triggered dataLayer object to the DB) we were all set up.
All that was left was to write one last test scenario (no sneak peek for that one). Up till now we have had one test per (one) GTM event, as we already mentioned. In this new test, we validated that the actual event fires when expected and the dataLayer variables (object properties) are as expected. Additionally, this last test we added would execute after all the other tests have finished (configuring this is a simple edit to playwrights config file and understanding some naming conventions). Here, we retrieved all the previously stored dataLayer objects and just compared them to the expected dataLayer variable values stored on Google’s Big Query.
And there you have it, after working it out, we are now comparing the actual result to the expected result – the very essence of testing!
By doing so we have increased our tracking teams confidence in the data they retrieve and ensured that the data is valid. All that’s left now is to make some business decisions with all that lovely, valid data. But let’s leave that for another day 😉


